|
|
 File by OCR
-
Version
4.0
File by OCR
-
Version
4.0
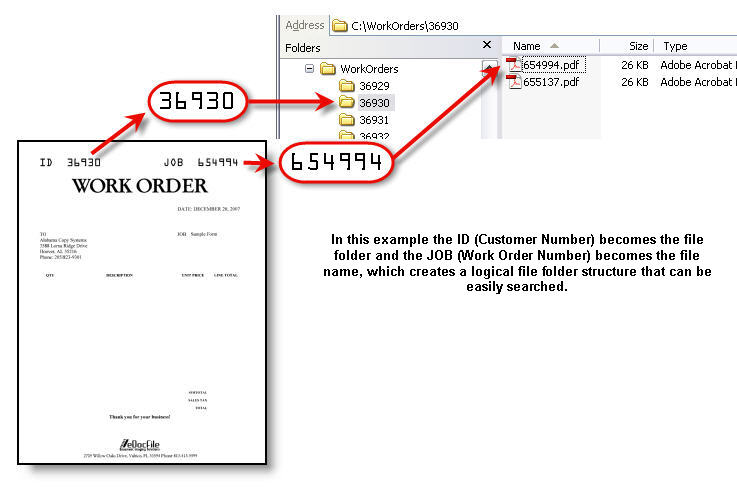
File by OCR automatically names files and places them
in a file folder structure based on the document's OCR
text contents. It can extract text from a searchable
PDF and name and file it, or it can extract the OCR
text and build a csv file. File by OCR uses Optical
Character Recognition on the entire document and then
parses the data contents, allowing the user to easily
capture and extract data from multi-page documents and
documents of various lengths such as sales receipts.
All processing of documents is done in a batch process
after scanning, allowing a user to move on to
something else while the OCR process is being carried
out.
File by OCR has the capability to monitor an unlimited
number of file folders that contain different document
types to be processed, making it ideal for use with a
copier that has a scan to file option. The program
also supports Twain Scanners and has an easy to use
interface that correctly places the file in the
|